FY.Bsc.Cs Sem-2 Based on Mumbai Unversity
Database Mangement System SEM 2 AlL 3 UNIT +IMPORTAN Question Bank Answer:-( Hand Written Google Drive Link )

1.Briefly explain Levels of Abstraction and Data Independence with diagrams.
Levels of Abstraction:
External Level (View Level): Represents how individual users or applications perceive the data. It provides a customized view tailored to specific user requirements.
Conceptual Level (Logical Level): Represents the entire database as a unified structure, independent of implementation details. It defines the logical structure of the database.
Internal Level (Physical Level): Represents how data is physically stored and accessed. It includes details such as data organization and storage structures.
Logical Data Independence: Allows changes to the logical level without affecting the view level or application programs.
Physical Data Independence: Allows changes to the physical level without affecting the logical level or view level.
Diagram:

2.Draw and explain architecture of DBMS.
DBMS Architecture
- The DBMS design depends upon its architecture. The basic client/server architecture is used to deal with a large number of PCs, web servers, database servers and other components that are connected with networks.
- The client/server architecture consists of many PCs and a workstation which are connected via the network.
- DBMS architecture depends upon how users are connected to the database to get their request done.
Types of DBMS Architecture
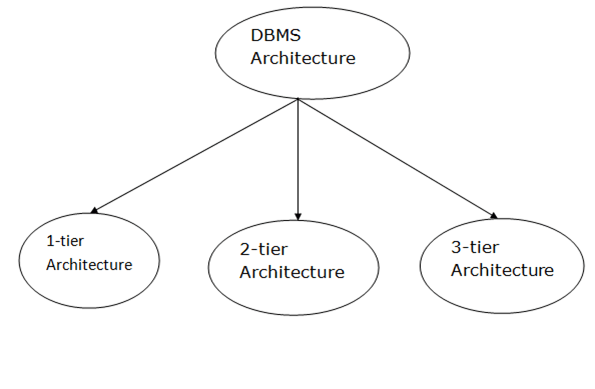
Database architecture can be seen as a single tier or multi-tier. But logically, database architecture is of two types like: 2-tier architecture and 3-tier architecture.
1-Tier Architecture
- In this architecture, the database is directly available to the user. It means the user can directly sit on the DBMS and uses it.
- Any changes done here will directly be done on the database itself. It doesn't provide a handy tool for end users.
- The 1-Tier architecture is used for development of the local application, where programmers can directly communicate with the database for the quick response.
2-Tier Architecture
- The 2-Tier architecture is same as basic client-server. In the two-tier architecture, applications on the client end can directly communicate with the database at the server side. For this interaction, API's like: ODBC, JDBC are used.
- The user interfaces and application programs are run on the client-side.
- The server side is responsible to provide the functionalities like: query processing and transaction management.
- To communicate with the DBMS, client-side application establishes a connection with the server side.
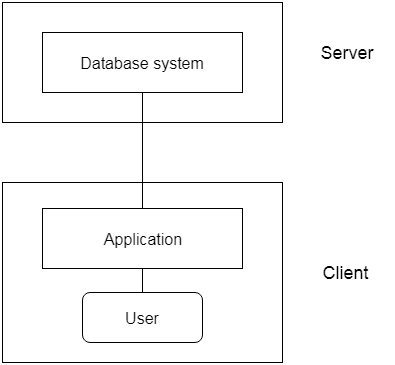
Fig: 2-tier Architecture
3-Tier Architecture
- The 3-Tier architecture contains another layer between the client and server. In this architecture, client can't directly communicate with the server.
- The application on the client-end interacts with an application server which further communicates with the database system.
- End user has no idea about the existence of the database beyond the application server. The database also has no idea about any other user beyond the application.
- The 3-Tier architecture is used in case of large web application.
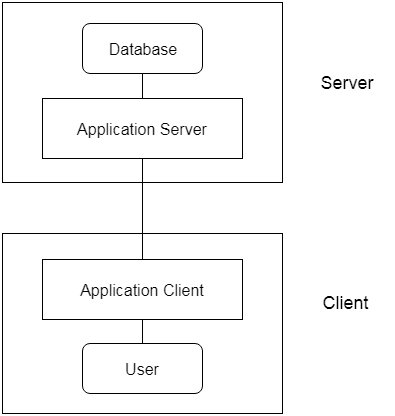
Fig: 3-tier Architecture
3.Briefly describe the Alter Command and keywords ADD, MODIFY, RENAME & DROP with syntax and examples.
The ALTER command in SQL is used to modify the structure of existing database objects, such as tables. It allows you to add, modify, rename, or drop columns and constraints within a table. Here's a brief description of the ALTER command along with the keywords ADD, MODIFY, RENAME, and DROP, including their syntax and examples
ADD:
- The ADD keyword is used with the ALTER command to add new columns or constraints to an existing table.
Syntax:
ALTER TABLE table_name ADD column_name datatype [constraint];
Example :
ALTER TABLE employees ADD email VARCHAR(255) NOT NULL;
MODIFY:
- The MODIFY keyword is used with the ALTER command to modify the data type or attributes of an existing column.
Syntax:
ALTER TABLE table_name MODIFY column_name new_datatype [constraint];
example:
ALTER TABLE employees MODIFY email VARCHAR(100);
RENAME:
- The RENAME keyword is used with the ALTER command to rename an existing column in a table.
Syntax:
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name;
Example
ALTER TABLE employees RENAME COLUMN email TO email_address;
DROP:
- The DROP keyword is used with the ALTER command to remove columns or constraints from an existing table.
Syntax:
ALTER TABLE table_name DROP column_name;
Example
ALTER TABLE employees DROP COLUMN email_address;
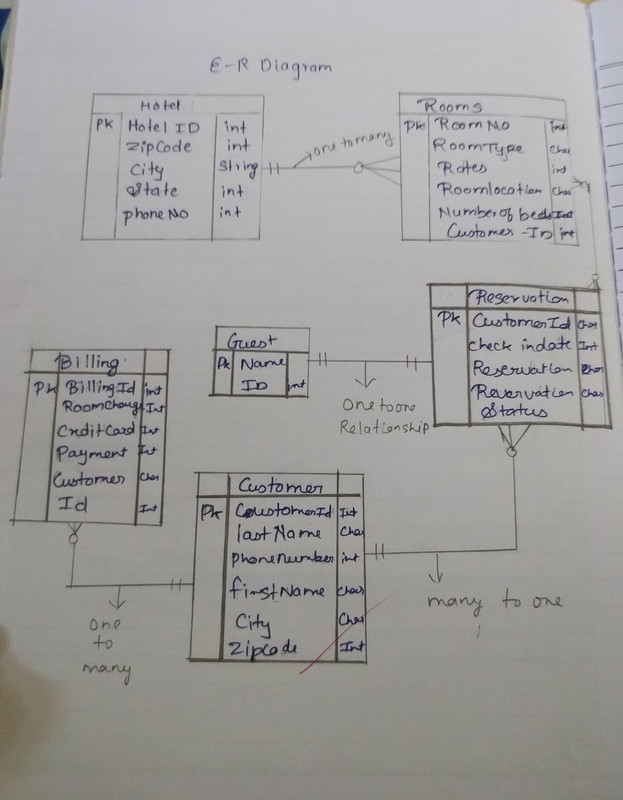
4.Draw an Entity Relationship (ER) diagram for the Hotel Management System.
5.Define the term Attribute. Explain the types of attributes with a suitable example for each.
An attribute in the context of a database represents a characteristic or property of an entity. It describes the various features or qualities associated with the entities in a database schema. Attributes help define the structure and properties of the data stored in a database.
There are different types of attributes, each with its own characteristics and behavior. Here are the main types of attributes along with examples for each:
Simple Attribute:
- A simple attribute is an atomic value that cannot be divided further into smaller components.
- It represents a single value associated with an entity.
- Example: In a database for employee records, "EmployeeID" can be a simple attribute. Each employee has a unique identifier represented by a single value.
Composite Attribute:
- A composite attribute is composed of multiple simple attributes grouped together.
- It represents a collection of related values treated as a single unit.
- Example: In a database for addresses, a "Full Address" attribute may be composed of sub-attributes such as "Street", "City", "State", and "Zip Code".
Derived Attribute:
- A derived attribute is computed or derived from other attributes in the database.
- It does not store data directly but is calculated based on other attributes.
- Example: In a database for sales transactions, a "Total Price" attribute can be derived from the "Unit Price" and "Quantity" attributes by multiplying them together.
Multi-valued Attribute:
- A multi-valued attribute can have multiple values for a single entity.
- It represents a set of values, rather than a single value.
- Example: In a database for a social media platform, the "Interests" attribute of a user may contain multiple interests such as "Music", "Sports", and "Travel".
Key Attribute:
- A key attribute uniquely identifies each entity within a database.
- It serves as a primary key or part of a primary key.
- Example: In a database for student records, "StudentID" can be a key attribute that uniquely identifies each student.
Null Attribute:
- A null attribute represents missing or unknown information.
- It indicates that a value has not been assigned or is not applicable for a particular entity.
- Example: In a database for customer feedback, the "Middle Name" attribute may be null for customers who do not have a middle name recorded.
6.Perform the following:
- Create table Course(c_id , c_name). Where c_id is the primary key.
- Create table student(roll_no , name , percentage,c_id) Where roll_no is the primary key, c_id is the foreign key and percentage is not null.
- Insert 2 record in each of the above tables
- Rename table Course to Stream.
- Delete the last record from the Student table.
In the context of the relational model in databases, a key is a data attribute or a combination of attributes that uniquely identifies each row or record in a table. Keys play a fundamental role in ensuring data integrity, enforcing constraints, and establishing relationships between tables. There are several types of keys in the relational model:
Primary Key (PK):
- A primary key is a unique identifier for each row in a table.
- It must have unique values and cannot contain NULL values.
- Each table can have only one primary key.
- Example: A "StudentID" column in a "Students" table can serve as the primary key, ensuring each student has a unique identifier.
Foreign Key (FK):
- A foreign key is a column or a set of columns in one table that refers to the primary key in another table.
- It establishes relationships between tables, enforcing referential integrity.
- It helps maintain consistency and integrity between related tables.
- Example: A "CourseID" column in a "Courses" table can be a foreign key referencing the "CourseID" column in a "Students" table, indicating which course each student is enrolled in.
Unique Key:
- A unique key is similar to a primary key but can allow NULL values.
- It ensures that each value in the key column(s) is unique but allows at least one NULL value.
- A table can have multiple unique keys, but only one primary key.
- Example: An "Email" column in a "Users" table can be a unique key, ensuring that each email address is unique but allowing some users to not have an email address.
Composite Key:
- A composite key consists of two or more columns that, together, uniquely identify each row in a table.
- It combines multiple attributes to form a unique identifier.
- Example: A combination of "DepartmentID" and "EmployeeID" columns in an "Employees" table can form a composite key, ensuring that each employee is uniquely identified within each department.
Candidate Key:
- A candidate key is a set of attributes that uniquely identify each row in a table.
- It is a potential candidate for being a primary key.
- Example: In a "Students" table, both "StudentID" and "SocialSecurityNumber" could serve as candidate keys, as they uniquely identify each student.
Super Key:
- A super key is a set of attributes that uniquely identifies each row in a table.
- It may contain more attributes than necessary to uniquely identify rows.
- Example: A combination of "StudentID", "FirstName", and "LastName" in a "Students" table can form a super key, as it uniquely identifies each student, but it contains more attributes than necessary to uniquely identify them.
- 8.Differentiate between Primary and Unique constraints.
Primary Key and Unique constraints are both used in relational databases to ensure the uniqueness of data within a table, but they serve slightly different purposes:
Primary Key Constraint:
- A Primary Key constraint uniquely identifies each record in a table.
- It ensures that the column or combination of columns designated as the primary key have unique values and cannot contain NULL values.
- Each table can have only one Primary Key constraint.
- The primary key is typically used as the main identifier for the table and is often used as a reference in foreign key constraints in other tables.
- Example: In a "Students" table, the "StudentID" column can be designated as the primary key, ensuring that each student has a unique identifier.
Unique Constraint:
- A Unique constraint ensures that the values in one or more columns are unique within the table.
- It allows for unique values but can allow NULL values unless specified otherwise.
- Unlike a primary key, a unique constraint does not automatically create an index or enforce the NOT NULL constraint.
- A table can have multiple unique constraints, and unique constraints can be applied to columns that are not intended to be primary keys.
- Example: In a "Users" table, the "Email" column can have a unique constraint, ensuring that each email address is unique across all user records but allowing some users to not have an email address.
normalization forms:
1. First Normal Form (1NF):
First Normal Form (1NF) is the simplest form of normalization in relational database design. A table is said to be in 1NF if it satisfies the following conditions:
- Each column in the table contains atomic (indivisible) values, meaning that each value in a column should be indivisible.
- Each column must have a unique name.
- The values in each column must be of the same data type.
Example: Consider a table named "Students" with the following columns: StudentID, Name, Subjects. If the "Subjects" column contains multiple subjects separated by commas like "Maths, Physics, Chemistry", then the table is not in 1NF. To normalize it into 1NF, you need to split the "Subjects" column into multiple rows, each containing a single subject.
2. Second Normal Form (2NF):
Second Normal Form (2NF) builds upon the concepts of 1NF and introduces additional requirements to remove partial dependencies. A table is in 2NF if it satisfies the following conditions:
- It is in 1NF.
- All non-key attributes are fully functionally dependent on the entire primary key.
Example: Consider a table named "Orders" with the following columns: OrderID (Primary Key), ProductID (Primary Key), ProductName, Quantity. If ProductName depends only on ProductID and not on OrderID, then there is a partial dependency. To normalize it into 2NF, you need to create a separate table for Product information, removing the partial dependency.
1NF ensures that each column contains atomic values, while 2NF ensures that there are no partial dependencies on the primary key. These normalization forms help in organizing data efficiently, reducing redundancy, and maintaining data integrity in relational databases.
14.What does DBA stand for? Explain the role of DBA in database protection.
DBA stands for Database Administrator. The role of a Database Administrator (DBA) is critical in managing and protecting databases within an organization. Here's an explanation of the DBA's role in database protection:
Role of DBA in Database Protection:
Security Implementation: DBAs play a crucial role in implementing and managing database security measures such as access controls, encryption, and authentication mechanisms to safeguard sensitive data from unauthorized access, modification, or disclosure.
User Management: DBAs are responsible for managing user accounts and permissions within the database system. They grant appropriate privileges to users based on their roles and responsibilities while ensuring that access is restricted to only the necessary data and functionalities.
Backup and Recovery: DBAs oversee the implementation of backup and recovery strategies to protect against data loss and system failures. They regularly perform database backups, maintain backup copies, and develop recovery plans to restore data in case of emergencies or disasters.
Monitoring and Auditing: DBAs continuously monitor database activities and performance to detect any anomalies or security breaches. They set up auditing mechanisms to track user actions, analyze audit logs, and investigate any suspicious activities to maintain the integrity and confidentiality of the database.
Patch Management: DBAs ensure that database systems are kept up-to-date with the latest security patches and updates. They apply patches promptly to address known vulnerabilities and mitigate potential risks to the database infrastructure.
In the context of databases, a view is a virtual table that is based on the result set of a SELECT query. Unlike base tables, which contain actual data, views do not store data themselves but provide a way to present data stored in one or more tables in a structured format. Views are defined by SQL queries and can be queried and manipulated like tables.
Advantages of using views include:
Data Abstraction:
- Views provide a layer of abstraction over the underlying tables, allowing users to interact with a simplified and tailored representation of the data.
- Users can access specific columns or rows of interest without needing to understand the complexities of the underlying database schema.
Security:
- Views can be used to enforce security policies by restricting access to sensitive data.
- DBAs can define views that expose only the necessary data to users while hiding the underlying structure and sensitive information.
Simplified Data Access:
- Views can simplify complex SQL queries by encapsulating joins, calculations, and aggregations into reusable view definitions.
- Users can query views directly without needing to write complex SQL statements, improving productivity and reducing errors.
Performance Optimization:
- Views can improve query performance by precomputing and caching query results.
- Materialized views, a type of view that stores the result set of the query in physical storage, can be used to improve performance for frequently accessed or resource-intensive queries.
Data Integrity:
- Views can enforce data integrity constraints by filtering or validating data before presenting it to users.
- DBAs can define views that enforce business rules and data validation checks, ensuring that users always access consistent and accurate data.
Simplified Data Modification:
- Views can be used to simplify data modification operations by providing a consistent interface for inserting, updating, and deleting data.
- Users can modify data through views using standard SQL DML (Data Manipulation Language) statements, with the underlying view definition handling the complexity of data manipulation.
Databases face various threats that can compromise the confidentiality, integrity, and availability of data. These threats can arise from both internal and external sources. Here are some common threats to databases:
Unauthorized Access:
- Unauthorized users gaining access to sensitive data by exploiting vulnerabilities in authentication mechanisms, weak passwords, or insufficient access controls.
- Attackers may attempt to bypass authentication mechanisms or use stolen credentials to gain unauthorized access to databases.
SQL Injection:
- SQL injection attacks occur when malicious SQL code is inserted into input fields or query parameters, allowing attackers to execute unauthorized SQL commands against the database.
- Attackers can use SQL injection to extract sensitive data, modify or delete database records, or execute administrative commands.
Data Breaches:
- Data breaches involve unauthorized access to confidential or sensitive data stored in databases.
- Breaches can occur due to insider threats, external attackers, or accidental exposure of data through insecure configurations or misconfigured permissions.
Data Manipulation:
- Attackers may attempt to manipulate or tamper with data stored in databases to disrupt business operations, sabotage systems, or commit fraud.
- Unauthorized modification or deletion of data can lead to data loss, corruption, or unauthorized changes to records.
Data Leakage:
- Data leakage refers to the unauthorized disclosure or exposure of sensitive data stored in databases.
- Leakage can occur through various channels, including insecure APIs, unencrypted communication channels, or misconfigured database permissions.
Denial of Service (DoS) Attacks:
- Denial of Service attacks aim to disrupt database services by overwhelming servers with a high volume of requests, causing them to become unresponsive or unavailable.
- DoS attacks can impact database availability and disrupt business operations, leading to downtime and financial losses.
Insider Threats:
- Insider threats involve malicious or negligent actions by authorized users, such as employees, contractors, or partners, who have access to database systems.
- Insiders may intentionally or unintentionally misuse their privileges to steal data, commit fraud, or compromise the security of databases.
Malware and Ransomware:
- Malicious software (malware) and ransomware can infect database servers, compromising the integrity and confidentiality of data.
- Malware may steal sensitive information, modify database records, or encrypt data to extort ransom payments from victims.
- 19. Explain in brief privileges in database.
Indexes in databases are data structures that improve the speed of data retrieval operations by providing quick access to rows based on the values of one or more columns. Different types of indexes are available, each with its own characteristics and use cases. Here's a brief overview of common types of indexes:
B-Tree Index:
- B-Tree (Balanced Tree) indexes are the most common type of index used in databases.
- They organize data in a hierarchical structure, allowing for efficient range queries, equality searches, and sorted retrieval of data.
- B-Tree indexes are suitable for most types of queries and are effective for both low and high cardinality columns.
Bitmap Index:
- Bitmap indexes represent sets of data using bitmap vectors, where each bit corresponds to a unique value in the indexed column.
- They are highly efficient for low-cardinality columns with a limited number of distinct values.
- Bitmap indexes are particularly useful for columns containing boolean or categorical data.
Hash Index:
- Hash indexes use a hash function to map keys to their corresponding storage locations.
- They provide fast access to data for equality searches but are not suitable for range queries or sorting operations.
- Hash indexes are effective for exact match lookups and are commonly used in in-memory databases or for indexing primary keys.
Full-Text Index:
- Full-Text indexes are specialized indexes used for searching text-based data, such as documents, articles, or web pages.
- They tokenize and index textual data, allowing for fast and efficient text search queries based on keywords or phrases.
- Full-Text indexes support advanced features like stemming, stop-word removal, and relevance ranking.
Spatial Index:
- Spatial indexes are designed for spatial data types, such as points, lines, or polygons, representing geographical or geometric features.
- They facilitate efficient spatial queries, such as finding nearby points, calculating distances, or performing spatial joins.
- Spatial indexes use specialized data structures like R-trees or quad-trees to organize and search spatial data efficiently.
Composite Index:
- Composite indexes are indexes that span multiple columns, allowing for efficient retrieval of data based on combinations of column values.
- They are useful for queries that involve multiple columns in the WHERE clause, ORDER BY clause, or JOIN conditions.
- Composite indexes can improve query performance by reducing the number of disk I/O operations needed to satisfy complex queries.
In the context of relational databases, the projection operation is used to select specific columns (attributes) from a table while discarding the rest of the columns. It produces a new relation (table) that contains only the selected columns, effectively reducing the dimensionality of the data.
The projection operation is denoted using the Greek letter π (pi) and is commonly written as π<sub>column1, column2, ...</sub>(table_name).
Here's an example to illustrate the projection operation:
Consider a table named "Students" with the following columns: StudentID, Name, Age, Gender, and Grade.
Students Table:
+-----------+-------------+-----+--------+-------+
| StudentID | Name | Age | Gender | Grade |
+-----------+-------------+-----+--------+-------+
| 101 | John Doe | 18 | Male | A |
| 102 | Jane Smith | 20 | Female | B |
| 103 | Alice Brown | 19 | Female | C |Now, suppose we want to perform a projection operation to select only the "StudentID" and "Name" columns from the "Students" table:
Projection (π) of StudentID and Name:
π<StudentID, Name>(Students)
+-----------+-------------+
| StudentID | Name |
+-----------+-------------+
| 101 | John Doe |
| 102 | Jane Smith |
| 103 | Alice Brown |
+-----------+-------------+In this example, the projection operation selects only the "StudentID" and "Name" columns from the "Students" table, resulting in a new table that contains only these two columns. The projection operation effectively reduces the dimensionality of the data and focuses on the specific attributes of interest.
22.Explain OnDeleteSetNull in referential integrity constraints..
In referential integrity constraints, specifically in the context of foreign key constraints, the ON DELETE SET NULL option defines the action to be taken when a referenced row in the parent table is deleted. When a row in the parent table is deleted, the foreign key values in the child table can either be set to NULL, cascaded (where the corresponding rows in the child table are also deleted), or restricted (where the delete operation is prevented if there are dependent rows in the child table). With ON DELETE SET NULL: 1. **When a referenced row is deleted from the parent table**: - The foreign key values in the child table that reference the deleted row are set to NULL. 2. **The referenced row is deleted from the parent table**: - The rows in the child table that reference the deleted row will no longer have a valid reference to the parent table. Therefore, to maintain referential integrity, the foreign key values are set to NULL instead. Here's a brief example to illustrate how ON DELETE SET NULL works: Consider two tables: "Parent" and "Child". **Parent Table:**
output
```
ParentID | ParentColumn
------------------------
1 | Data1
2 | Data2
3 | Data3
```
output
**Child Table:** ``` ChildID | ParentID (Foreign Key) | ChildColumn --------------------------------------------- 101 | 1 | ChildData1 102 | 2 | ChildData2 103 | 3 | ChildData3 ``` If we define the foreign key constraint with ON DELETE SET NULL on the "ParentID" column in the "Child" table, and then delete the row in the "Parent" table with "ParentID = 2", the resulting state of the "Child" table would be: **Child Table (After deletion of ParentID = 2):**
Output ``` ChildID | ParentID (Foreign Key) | ChildColumn --------------------------------------------- 101 | 1 | ChildData1 102 | NULL | ChildData2 103 | 3 | ChildData3 ``` As you can see, the foreign key value in the "Child" table corresponding to the deleted row in the "Parent" table is set to NULL, maintaining referential integrity while allowing the deletion of the parent row.
23.Differentiate between weak and strong entity. same answer for 47 the Question
| Strong Entity | Weak Entity |
|---|---|
| - A strong entity has its unique identifier, known as a primary key. | - A weak entity lacks its unique identifier or primary key. |
| - It can exist independently without relying on any other entity for identification. | - A weak entity depends on the existence of another entity, known as the owner entity, for identification. |
| - Attributes uniquely identify each instance of the entity. | - Identified by a combination of their attributes and the primary key of the owning entity. |
| - Example: "Student" entity in a university database with "student_id" as a unique identifier. | - Example: "CourseOffering" entity in a university database, identified by a combination of its attributes and the primary key of the "Course" entity. |
Specialization is a concept in the entity-relationship model (ERM) where a higher-level entity (the superclass or parent entity) is divided into one or more lower-level entities (the subclasses or child entities) based on common characteristics or attributes. Each subclass inherits the attributes and relationships of the superclass but may also have additional attributes or relationships specific to it.
Here's an example to illustrate specialization:
Consider a superclass entity called "Vehicle." The "Vehicle" entity represents all types of vehicles, including cars, trucks, and motorcycles. However, each type of vehicle has unique attributes and behaviors that distinguish it from others. We can specialize the "Vehicle" entity into three subclasses: "Car," "Truck," and "Motorcycle."
Superclass Entity: Vehicle
- Attributes: VehicleID, Make, Model, Year, Color
Subclass Entities:
Car
- Attributes: VehicleID (inherited), Make (inherited), Model (inherited), Year (inherited), Color (inherited), NumDoors, TransmissionType
Truck
- Attributes: VehicleID (inherited), Make (inherited), Model (inherited), Year (inherited), Color (inherited), PayloadCapacity, TruckType
Motorcycle
- Attributes: VehicleID (inherited), Make (inherited), Model (inherited), Year (inherited), Color (inherited), EngineDisplacement, FuelType
In this example, "Vehicle" is the superclass entity, and "Car," "Truck," and "Motorcycle" are its subclasses. Each subclass inherits the common attributes of the superclass (VehicleID, Make, Model, Year, Color), but also has additional attributes specific to the type of vehicle.
Specialization allows us to model the hierarchy and relationships between entities in a more structured and organized manner. It enables us to capture both common characteristics shared by all entities in the superclass and specific characteristics unique to each subclass. Additionally, specialization facilitates more precise querying and analysis of data by allowing us to focus on subsets of entities with similar attributes and behaviors.
25.State and explain in brief advantages of DBMS.
Database Management Systems (DBMS) offer several advantages that make them essential tools for managing and organizing data efficiently. Here are some key advantages:
Data Integration and Centralization :
- DBMS enables organizations to integrate data from multiple sources into a single database, eliminating data silos and redundancy.
- Centralized data storage facilitates data sharing, collaboration, and consistency across departments and applications.
Data Security :
- Robust security features in DBMS protect sensitive data from unauthorized access, modification, or deletion.
- Security mechanisms like access controls, encryption, authentication, and auditing enforce data security policies and regulatory compliance.
Data Consistency and Integrity :
- DBMS ensures data consistency and integrity by enforcing referential integrity constraints, validation rules, and transaction management.
- ACID properties (Atomicity, Consistency, Isolation, Durability) ensure reliable processing of transactions and maintain data integrity.
Data Accessibility and Scalability :
- Efficient data retrieval and manipulation capabilities in DBMS, through query languages (e.g., SQL) and indexing mechanisms, enhance data accessibility.
- Scalability features such as partitioning, replication, and clustering support handling increasing data volumes and user transactions.
Data Recovery and Backup :
- DBMS provides mechanisms for data backup, recovery, and disaster recovery to ensure data availability and minimize the risk of data loss.
- Backup and recovery strategies, including full backups, incremental backups, and point-in-time recovery, contribute to data resilience.
- 26.Draw and explain architecture of DBMS.
The architecture of a Database Management System (DBMS) can be divided into three main layers: the external level, the conceptual level, and the internal level. Here's a brief overview of each layer:
External Level (View Level):
- The external level, also known as the view level or user level, is the topmost layer of the DBMS architecture.
- It represents the interaction between users and the database system, providing different views or perspectives of the database to different users or user groups.
- Users interact with the database through user interfaces, applications, or query languages tailored to their specific needs and roles.
- Each user or user group may have its own customized view of the database, presenting only the relevant subset of data and hiding the underlying complexities of the database schema.
Conceptual Level (Logical Level):
- The conceptual level, also known as the logical level, is the middle layer of the DBMS architecture.
- It represents the logical structure and organization of the entire database, independent of any specific implementation details or physical storage considerations.
- The conceptual schema defines the entities, attributes, relationships, and constraints that constitute the database model, typically represented using a high-level data model such as the Entity-Relationship (ER) model or the Relational model.
- The conceptual schema serves as a blueprint for the database design and provides a unified and abstracted view of the database that is shared among all users and applications.
Internal Level (Storage Level):
- The internal level, also known as the storage level or physical level, is the bottommost layer of the DBMS architecture.
- It represents the physical storage and organization of data within the database system, including data structures, access methods, and storage allocation mechanisms.
- The internal schema defines how data is stored on disk, including details such as file organization, indexing structures, data compression techniques, and optimization strategies.
- The internal schema is optimized for efficient data storage, retrieval, and manipulation, taking into account factors such as disk space utilization, access speed, and concurrency control.
Explanation:
- The external level provides personalized views of the database to individual users or user groups, allowing them to interact with the database based on their specific requirements and preferences.
- The conceptual level defines the overall logical structure of the database, ensuring data independence and abstraction from the underlying implementation details.
- The internal level manages the physical storage and organization of data on disk, optimizing performance and resource utilization.
- Digram refer class notes
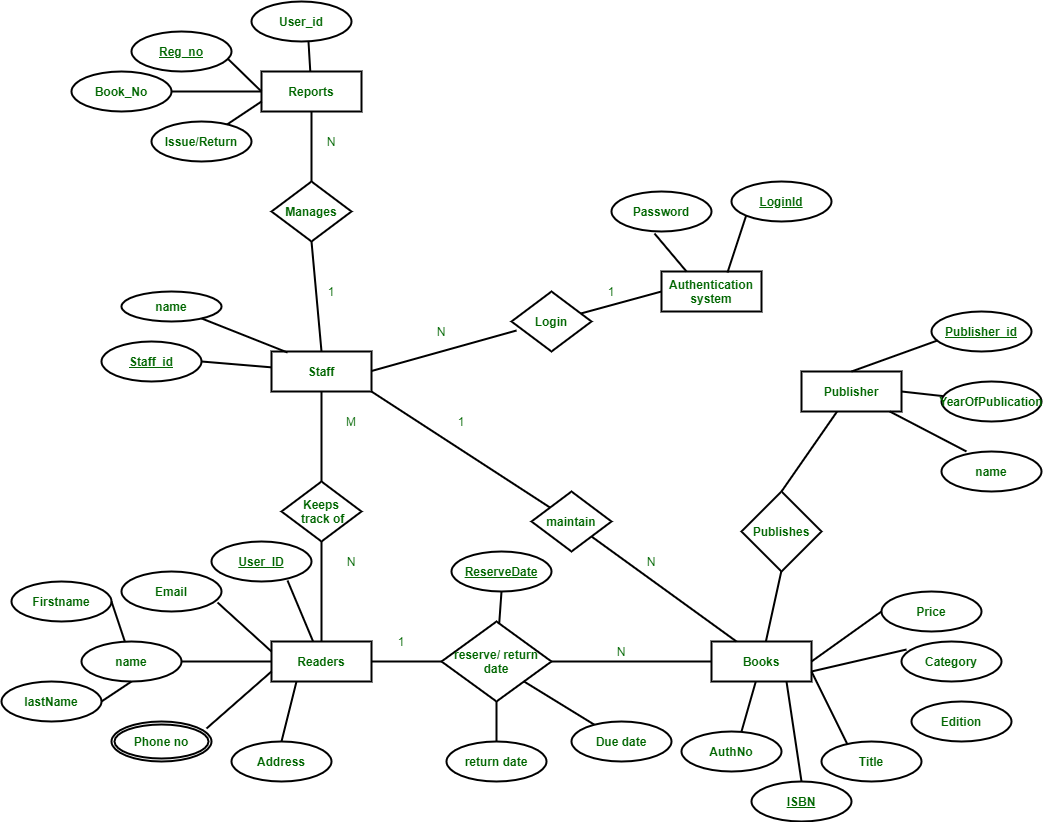
Entity: Attribute: - Represents real-world objects, concepts, or things. - Represents characteristics or properties of entities. - Typically corresponds to nouns or noun phrases. - Serve as building blocks of entities. - Each entity is uniquely identifiable. - Each attribute is represented as a column in the entity's table. - Examples include "Customer," "Product," "Employee," etc. - Examples include "CustomerID," "CustomerName," "ProductID," etc. - 28.Draw an Entity Relationship (ER) diagram for the Library Management system.
29.Define the term Attribute. Explain the types of attributes with a suitable example for each.
attribute is a characteristic or property that describes an entity. Attributes provide additional information about the entity and help define its structure and behavior within the database. Each entity typically has multiple attributes associated with it, representing different aspects or features of the entity. Here's an explanation of the types of attributes commonly used in databases, along with examples for each:
Simple Attribute:
- A simple attribute is an attribute that cannot be divided into smaller subparts.
- It represents a single value associated with the entity.
- Example: "CustomerName" in a "Customer" entity, "EmployeeID" in an "Employee" entity.
Composite Attribute:
- A composite attribute is an attribute that can be divided into smaller subparts, each representing a more granular aspect of the attribute.
- It consists of multiple simple attributes grouped together to represent a single attribute.
- Example: "Address" attribute in a "Customer" entity may include subattributes like "StreetAddress," "City," "State," and "PostalCode."
Derived Attribute:
- A derived attribute is an attribute whose value can be derived or calculated from other attributes in the database.
- It does not need to be stored explicitly in the database because its value can be determined based on other attributes.
- Example: "Age" attribute in an "Employee" entity can be derived from the "DateOfBirth" attribute by subtracting the birth date from the current date.
Multi-valued Attribute:
- A multi-valued attribute is an attribute that can have multiple values associated with it for a single entity instance.
- It represents a set of values rather than a single value.
- Example: "PhoneNumbers" attribute in a "Customer" entity may contain multiple phone numbers associated with a single customer, such as home, work, and mobile numbers.
Key Attribute:
- A key attribute is an attribute whose values uniquely identify each entity instance within an entity set.
- It serves as the primary key or part of the primary key of the entity.
- Example: "EmployeeID" attribute in an "Employee" entity serves as the primary key, uniquely identifying each employee record in the database.
Null Attribute:
- A null attribute is an attribute that may or may not have a value associated with it.
- It represents an unknown or undefined value.
- Example: If a "Customer" entity has an optional "MiddleName" attribute, it may be null for customers who do not have a middle name recorded in the database.

Display only the names of employees whose age is above 30.
Ans- SELECT E_Name FROM Employee WHERE E_AGE > 30;
Display all columns from employees whose salary is between 50000 to 80000.
Ans- SELECT *
FROM Employee WHERE E_Salary BETWEEN 50000 AND 80000;
Display all the records of the table in ascending order of their salary.
Ans- SELECT *
FROM Employee ORDER BY E_Salary ASC;
Find out the average salary using aggregate function.
Ans- SELECT AVG(E_Salary) AS AverageSalary
FROM Employee;
Display only those employee names ending with ‘a’.
Ans- SELECT E_Name
FROM Employee WHERE E_Name LIKE '%a';
- 31.What is a Relations Model? List and explain its characteristics, advantages and disadvantages.
The Relational Model is a conceptual framework for organizing and structuring data in a database management system (DBMS). It was introduced by Edgar F. Codd in 1970 and has since become the most widely used data model for designing relational databases. Here are the characteristics, advantages, and disadvantages of the Relational Model:
characteristics of the Relational Model:
Tabular Structure:
- Data is organized into tables (relations), consisting of rows (tuples) and columns (attributes). This tabular structure provides a clear and intuitive way to represent data.
Keys:
- Each table has a primary key, which uniquely identifies each row within the table. Foreign keys establish relationships between tables, ensuring data integrity and enforcing referential integrity.
Structured Query Language (SQL):
- SQL is used to query and manipulate data stored in relational databases. It provides a standardized language for database interactions, allowing users to retrieve, insert, update, and delete data efficiently.
Advantages of the Relational Model:
Simplicity and Ease of Use:
- The tabular structure of the Relational Model is intuitive and easy to understand, making it accessible to users and developers.
Data Integrity:
- The Relational Model enforces integrity constraints to ensure data consistency and accuracy, reducing the risk of errors and inconsistencies.
Scalability:
- Relational databases can scale to handle large volumes of data and support concurrent users, making them suitable for enterprise-level applications.
Disadvantages of the Relational Model:
Performance Overhead:
- Join operations and complex queries in relational databases can sometimes lead to performance overhead, especially with large datasets.
Limited Support for Hierarchical and Network Structures:
- Relational databases are not well-suited for representing hierarchical or network data structures, which may require additional modeling or denormalization.
Complexity in Schema Evolution:
- Making changes to the database schema, such as adding or modifying tables or relationships, may require careful planning and coordination to maintain data integrity and compatibility with existing applications.
Primary Key Constraint Unique Constraint - Uniquely identifies each record in a table. - Ensures values in specified column(s) are unique, allowing null values. - Ensures values in specified column(s) are unique and not null. - Enforces uniqueness but not necessarily for identifying each record uniquely. - Automatically creates a unique index on the specified column(s). - Allows multiple unique constraints within a table. - Typically used as foreign keys in related tables for referential integrity. - Creates unique indexes on the specified column(s), similar to primary keys. - Example: In a "Students" table, the "StudentID" column could be designated as the primary key. - Example: In a "Users" table, the "Email" column could have a unique constraint to ensure each email address is unique.
Math functions, also known as mathematical functions or operators, are used in programming and database systems to perform various mathematical operations on numerical data. These functions allow for calculations such as addition, subtraction, multiplication, division, rounding, exponentiation, and more. Here's a brief overview of some common math functions with examples:
Addition (+):
- The addition function is used to add two or more numbers together.
- Example:
3 + 5equals8.
Subtraction (-):
- The subtraction function is used to subtract one number from another.
- Example:
10 - 7equals3.
Multiplication (*):
- The multiplication function is used to multiply two or more numbers together.
- Example:
4 * 6equals24.
Division (/):
- The division function is used to divide one number by another.
- Example:
15 / 3equals5.
Modulus (%):
- The modulus function returns the remainder of a division operation.
- Example:
10 % 3equals1(because 10 divided by 3 equals 3 with a remainder of 1).
Square Root (sqrt or √):
- The square root function returns the square root of a number.
- Example:
sqrt(25)or√25equals5(because the square root of 25 is 5).
Absolute Value (abs):
- The absolute value function returns the distance of a number from zero.
- Example:
abs(-7)equals7(because the absolute value of -7 is 7).
Round (round):
- The round function rounds a number to the nearest integer.
- Example:
round(3.7)equals4(because 3.7 rounded to the nearest integer is 4).
Normalization is the process of organizing and structuring a relational database in such a way that reduces data redundancy and dependency. It involves breaking down large tables into smaller, more manageable ones and establishing relationships between them. The objective of normalization is to eliminate data anomalies such as insertion, update, and deletion anomalies, ensuring data integrity and minimizing redundancy.
Advantages:
Reduction of Data Redundancy:
- Normalization eliminates data redundancy by organizing data into smaller, more focused tables.
- Reducing redundancy saves storage space and ensures data consistency, as there is only one copy of each piece of data.
Improved Data Integrity:
- By reducing redundancy and dependency, normalization helps maintain data integrity.
- Data anomalies such as insertion, update, and deletion anomalies are minimized, ensuring that the database remains accurate and reliable.
Simplified Database Maintenance:
- With normalized tables, database maintenance tasks such as adding, updating, and deleting records become simpler and less error-prone.
- Changes to the database structure are easier to manage, as modifications typically only need to be made in one place.
Enhanced Query Performance:
- Normalized databases often result in improved query performance, as smaller tables with fewer attributes require less processing power to retrieve data.
- Optimized database design allows for faster query execution, leading to better overall system performance.
Facilitates Scalability and Flexibility:
- A normalized database is more scalable and adaptable to changes in data requirements.
- As the database grows or evolves, normalized tables can accommodate new data and relationships without significant restructuring.
In SQL, transactions allow you to group one or more SQL operations into a single logical unit of work, ensuring that either all operations within the transaction are successfully completed, or none of them are. Two essential commands used to manage transactions in SQL are COMMIT and ROLLBACK.
COMMIT:
- Permanently saves the changes made within a transaction to the database.
- Once executed, all changes within the transaction become permanent and visible to other users.
- Syntax:
COMMIT; - Example: After updating salaries for employees in department 10, executing
COMMIT;ensures that the changes are permanently saved to the database.
ROLLBACK:
- Used to undo all changes made within a transaction and restore the database to its state before the transaction began.
- If executed, all changes made within the transaction are discarded, and the database returns to its previous state.
- Syntax:
ROLLBACK; - Example: If a ROLLBACK statement is executed before committing a transaction that deletes orders, all deleted orders are restored, and the database is returned to its state before the transaction began.
Transactions ensure consistency and integrity in database operations, even in the presence of errors or unexpected events. They are initiated with a BEGIN TRANSACTION statement and terminated with either a COMMIT or ROLLBACK statement.
DBA stands for Database Administrator. A Database Administrator is responsible for the management, maintenance, and security of a database system. Their role is critical in ensuring the efficient operation, availability, and security of the database environment. Here's how a DBA contributes to database protection:
Database Security Implementation:
- DBAs are responsible for implementing security measures to protect the database from unauthorized access, data breaches, and malicious activities.
- They set up user authentication and authorization mechanisms to control access to the database, ensuring that only authorized users can view, modify, or delete data.
- DBAs also configure encryption techniques to protect sensitive data stored in the database, ensuring that it remains secure both at rest and in transit.
Security Monitoring and Auditing:
- DBAs monitor the database system continuously to detect and respond to security threats and vulnerabilities.
- They set up auditing mechanisms to track user activities, such as logins, logouts, and data modifications, to identify any suspicious or unauthorized behavior.
- By regularly reviewing audit logs and security reports, DBAs can proactively identify security risks and take corrective actions to mitigate them, such as revoking user privileges or applying security patches.
Backup and Recovery Planning:
- DBAs develop backup and recovery strategies to ensure data availability and integrity in case of data loss, corruption, or system failures.
- They implement regular backup schedules to create copies of the database and transaction logs, allowing for data restoration in the event of a disaster or security incident.
- DBAs also conduct periodic data recovery tests to validate backup procedures and ensure that critical data can be restored within acceptable timeframes.
Patch Management and Vulnerability Remediation:
- DBAs are responsible for applying software patches and updates to the database management system (DBMS) and associated software components to address security vulnerabilities and software bugs.
- They stay informed about the latest security advisories and patches released by the DBMS vendors and apply them promptly to protect the database system from known vulnerabilities.
- DBAs perform regular vulnerability assessments and security scans to identify and remediate potential security weaknesses in the database infrastructure.
Database Performance Optimization:
- While not directly related to security, optimizing database performance indirectly contributes to database protection by reducing the risk of security incidents caused by system slowdowns or resource constraints.
- DBAs optimize database performance by tuning database configurations, optimizing query execution plans, and monitoring resource utilization to ensure efficient operation and responsiveness.
- 40.Explain the creating and dropping views with suitable examples
**Creating a View:** To create a view, use the `CREATE VIEW` statement followed by the view's name and the `AS` keyword with a SELECT statement defining the view's data. Example: ```sql CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition; ``` Dropping a View:* To drop a view, use the `DROP VIEW` statement followed by the view's name. Example: DROP VIEW view_name; These statements allow for the creation and deletion of views, which are virtual tables generated by queries to simplify data access and enhance security in relational databases.
- 41.Define Index. Write the commands for creating, altering and dropping an index.
Functional dependency in a database refers to the relationship between attributes (columns) within a table, where the value of one attribute uniquely determines the value of another attribute. There are several types of functional dependencies:
Full Functional Dependency:
- A full functional dependency occurs when the value of one attribute (or a set of attributes) uniquely determines the value of another attribute, and no proper subset of that attribute(s) has the same dependency.
- Example: In a table of employees where "employee_id" uniquely determines "employee_name," and no subset of "employee_id" has the same dependency on "employee_name."
Partial Functional Dependency:
- A partial functional dependency occurs when the value of one attribute (or a set of attributes) uniquely determines the value of another attribute, but some proper subset of that attribute(s) also has the same dependency.
- Example: In a table of orders where "order_id" uniquely determines "customer_id" and "product_id," but "customer_id" also determines "product_id." In this case, "customer_id" is a proper subset of "order_id," and both determine "product_id."
Transitive Dependency:
- A transitive dependency occurs when the value of one non-key attribute determines the value of another non-key attribute through a chain of functional dependencies.
- Example: In a table of courses where "course_id" determines "department_id" and "department_id" determines "department_name," the dependency of "department_name" on "course_id" is transitive.
Multivalued Dependency:
- A multivalued dependency occurs when the presence of one or more rows in a table implies the presence of certain values in another set of attributes, regardless of the values in other columns.
- Example: In a table of employee skills where "employee_id" determines "skill" and "skill" determines "certification," if an employee has a particular skill, they must have a corresponding certification for that skill.
- 43.Explain in brief grant and revoke.
| GRANT | REVOKE |
|---|---|
| - Grants specific privileges to users or roles. | - Revokes previously granted privileges from users or roles. |
| - Privileges include operations like SELECT, INSERT, etc. | - Removes specified privileges from users or roles. |
| - Syntax: | - Syntax: |
| ` | ``` |
| GRANT privilege_name | REVOKE privilege_name |
| ON object_name | ON object_name |
| TO {user_name | PUBLIC | role_name} [WITH GRANT OPTION]; | FROM {user_name | PUBLIC | role_name}; |
| - Example: | - Example: |
| ```sql | ```sql |
| GRANT SELECT, INSERT ON employees TO user1; | REVOKE INSERT ON employees FROM user1; |
| ``` | ``` |
| - Grants SELECT and INSERT privileges to "user1" on the "employees" table. | - Revokes INSERT privilege from "user1" on the "employees" table. |
In the realm of databases, indexes are vital for efficient data retrieval and management. They provide a structured way to access data quickly, akin to how an index in a book helps locate specific information. There are several types of indexes commonly used in database systems:
Single-Column Index:
- A single-column index is the simplest form of an index and is created on a single column of a table.
- It speeds up queries that involve filtering or sorting data based on the indexed column.
- Example: Creating an index on the "employee_id" column of an "employees" table.
Composite Index:
- A composite index, also known as a multi-column or compound index, is created on multiple columns of a table.
- It is useful for queries that involve filtering or sorting data based on multiple columns.
- Example: Creating an index on both the "last_name" and "first_name" columns of an "employees" table.
Unique Index:
- A unique index ensures that all values in the indexed column(s) are unique, i.e., no duplicate values are allowed.
- It enforces data integrity by preventing duplicate entries in the indexed column(s).
- Example: Creating a unique index on the "email" column of a "users" table to ensure each email address is unique.
Clustered Index:
- A clustered index determines the physical order of rows in a table based on the indexed column(s).
- It is often created automatically for the primary key column(s) of a table.
- Example: Creating a clustered index on the "order_date" column of an "orders" table to physically order the rows based on the date of the order.
Non-Clustered Index:
- A non-clustered index does not affect the physical order of rows in a table and is stored separately from the data.
- It contains pointers to the corresponding rows in the table based on the indexed column(s).
- Example: Creating a non-clustered index on the "product_name" column of a "products" table to speed up searches for product names.
Bitmap Index:
- A bitmap index is a special type of index used for columns with a limited number of distinct values, such as boolean or categorical data.
- It uses bitmaps to represent the presence or absence of each value in the indexed column(s), resulting in compact storage.
- Example: Creating a bitmap index on the "gender" column of a "customers" table to quickly retrieve male or female customers.
Strong Entity Weak Entity - A strong entity has its unique identifier, known as a primary key. - A weak entity lacks its unique identifier or primary key. - It can exist independently without relying on any other entity for identification. - A weak entity depends on the existence of another entity, known as the owner entity, for identification. - Attributes uniquely identify each instance of the entity. - Identified by a combination of their attributes and the primary key of the owning entity. - Example: "Student" entity in a university database with "student_id" as a unique identifier. - Example: "CourseOffering" entity in a university database, identified by a combination of its attributes and the primary key of the "Course" entity
- 48.Explain Generalization with suitable example.
Generalization, in the context of database design and modeling, refers to the process of creating a new, more general entity from a set of more specialized entities. It involves identifying common attributes and relationships among existing entities and abstracting them into a higher-level entity. This higher-level entity captures the shared characteristics of its sub-entities, allowing for more efficient and simplified data management.
Here's an example generalization:
Consider a database for a retail store that sells various types of products, including electronics, clothing, and books. Initially, you might have separate entities for each product type:
Electronics:
- Attributes: product_id, name, price, manufacturer, model_number
Clothing:
- Attributes: product_id, name, price, brand, size, color
Books:
- Attributes: product_id, name, price, author, genre, ISBN
Comments
Post a Comment